
Models>
Anime Consistency - [v2 Flux1-dev / v1.1 PDXL ]
No Images Found
Try Our Text To Image Demo
Quick Generate
Model Description by Creator
V2 Documentation:
Last night I was very tired, so I didn't finish compiling the full writeup and findings. Expect it asap, probably during the day while I'm at work I'll be running tests and marking values.
Flux Training Introduction:
Formerly, PDXL only required a small handful of images with danbooru tags to produce finetuned results comparable to NAI. Less images in that case was a strength due to it reducing potential, in this case less images did not work. It needed something, more. Some oomph with some power.
The model has a lot there, but the differentiations between the various learned data is considerably higher variance than expected at first. More variance means more potentials, and I couldn't figure out why it would work with the high variance.
After a bit of research I found that the model itself is so powerful BECAUSE of this. It can produce images that are "DIRECTED" based on depth, where the image is segmented and layered over another image using the noise of another image kind of like a guidepost to overlay atop of. It got me thinking, how exactly can I train >>THIS<< without destroying the model's core details. I was first thinking about how to do this with resizing, then I remembered bucketing duh. So this leads to the first piece here.
I basically went into this blind, setting settings based on suggestions and then determining outcome based on what I saw. It's a slow process, so I've been researching and reading papers on the side to speed things along. If I had the mental bandwidth I'd just do everything at once, but I'm only one person after all and I do have work to do. I basically threw the kitchen sink at it. If I had more attention to spare I'd have run 50 of these things at once, but I legitimately don't have the time of day to set something like that up. I could pay for it, but I can't set it up.
I went with what I thought would be the best format based on my experience with SD1.5, SDXL, and PDXL lora trainings. It turned out OKAY, but there's definitely something distinctly wrong with these and I'll get into details as I go.
Training Formatting:
I ran a few tests.
Test 1 - 750 random images from my danbooru sample:
UNET LR - 4e-4
I noticed most of the other elements didn't matter much and could be left default, except the attention to resolution bucketing.
1024x1024 only, cropped center
Between 2k-12k steps
I chose 750 random images from one of the random danbooru tag pools and ensured the tags were uniform.
Ran moat tagger on them and appended the tags to the tag file, ensuring the tags didn't overwrite.
The outcome wasn't promising. The chaos is expected. Introduction of new human elements such as genitalia was either hit or miss, or simply didn't exist most of the time. That's pretty much in line with everyone else's findings I've seen.
I DID NOT expect the entire model to suffer though, as the tags oftentimes didn't overlap I thought.
I ran this test twice and have two useless loras at about 12k steps each. Testing the 1k to 8k showed nearly nothing useful in deviation towards any sort of goal, even paying close attention to the tag pool's peaks and curves.
There's something else here. Something I missed, and I don't think it's a humanistic or clip description. There's something... more.
Around this failure point I made a discovery. This depth system, is interpolative and based on two entirely different and deviant prompts. These two prompts are in fact interpolative and cooperative. How it determines this use is unknown to me, but I'll be reading the papers today to figure out the math involved.
Test 2 - 10 images:
UNET LR - 0.001 <<< very powerful LR
256x256, 512x512, 768x768, 1024x1024
The initial steps were showing some deviation, similar to how much burn it imposed into the SD3 tests. It wasn't good though. The bleeding started at around step 500 or so. It was basically useless by step 1000. I know I'm basically using repeat here, but it definitely seemed to be a good experiment to fail.
Deviations are highly damaging here. It introduces a new context element, and then turns it into a snack machine. Replaces people's elements with nearly nothing useful or completely burned artifacts similar to how a badly set up inpaint happens. It was interesting how much damage FLUX can endure and STILL function. This test was quite potent showing FLUX's resilience, and it was damn resistant to my attempts.
This was a failure, require additional tests with different settings.
Test 3 - 500 pose images:
UNET LR - 4e-4 <<< This should require this divided by 4 and given twice the steps.
FULL bucketing - 256x256, 256x316, etc etc etc. I let it go wild and gave it a ton of images of various sizes and let it bucket everything. It was quite the unexpected outcome.
The outcome is LITERALLY the core of this consistency model, that's how powerful the outcome was. It seems to have done a bit more damage than I thought, but it was actually quite the thing.
Something to note; Anime generally doesn't use depth of field. This model seems to THRIVE on depth of field and blur to differentiate depth. There need to be a type of depth controlnet applied to these images to ensure depth variance, but I'm not sure off the cuff how to pull this one off. Training depth maps along with normal maps might work, but it also might completely destroy the model due to the model not having negative prompting.
More tests necessary. Additional training data required. Additional information required.
Test 4 - 5000 consistency bundle:
UNET LR - 4e-4 <<< This should be divided by 40 and given 20x the steps, give or take. Training something like this into the core model isn't simple, nor is it something that can be done quickly. The math isn't good with the current process to ensure the core model isn't broken, so I ran this and released the initial findings.
I had written up a whole section here plus a follow-up section and I was leading up to my findings section but I clicked back on my mouse button and it removed the whole thing so I'll need to rewrite it later.
The big failures:
The learning rate was WAY TOO HIGH for my initial 12k step loras. The entire system is based on gradient learning yes, but the rate at which I taught the thing was TOO HIGH for it to actually retain the information without it breaking the model. Simply put, I didn't burn them, I retrained the model to do what I wanted. The problem is, I didn't know what i wanted, so the entire system was based on a series of things that were not directed and without gradient depth. So it was doomed to fail, more steps or not.
STYLE for FLUX isn't what people think style IS based on PDXL and SD1.5. The gradient system will stylize things yes, but the entire structure heavily suffers when you attempt to impose TOO MUCH information too quickly. It's HIGHLY destructive, in comparison to PDXL loras which were more of an imposition set of loras. They would AUGMENT what was already there considerably more than training entirely new information into something.
Critical Findings:
ALPHA, ALPHA, and MORE ALPHA<<<< This system runs so heavily on alpha gradients that it's not funny. Everything MUST be specifically handled to handle alpha gradients based on photograph based details. distance, depth, ratio, rotation, offset, and so on are all key integral pieces to this model's composition and to create a proper compositional stylizer the entire thing needs those details in more than a single prompt.
EVERYTHING must be described properly. Simple danbooru tagging is essentially just style. You're forcing the system to recognize the style of the system you wish to implement, so you cannot simply impose new concepts without including the necessary concept allocation tags. Otherwise the style and concept linker will fail, giving you absolute garbage output. Garbage in, garbage out.
Pose training is HIGHLY potent when using LARGE amounts of pose information. The system ALREADY recognizes most of the tags, we just don't know what it recognizes yet. Pose training to link what IS THERE to what YOU WANT using specific tags, is going to be highly potent for tag organization and finetuning.
Step Documentation;
v2 - 5572 images -> 92 poses -> 4000 steps FLUX
The original goal to bring NAI to SDXL has now been applied to FLUX as well. Stay tuned for more versions in the future.
Stability testing required, so far it's showing some distinct capability beyond anything PDXL can handle. It needs additional training, but it's substantially more powerful than expected at such a low step count.
I believe the first layer of pose training is only about 500 images give or take, so that should be what's mostly cutting through. The full training data will be released on HuggingFace when I get together an organized image set and count. I don't want to release the incorrect images or leave garbage in the mix that I picked out.
v1 - 111 images -> 10 poses ->> 4 layered concepts ->>> 12,500 steps
Stability 6/10 - Requires additional concept feature training data and information for baseline pose consistency. Beyond expectations.
v1.1 - 190 images -> 10 poses ->> 10 layered concepts ->>> 20,000 steps - Full retrain
Stability 8/10 - Requires additional poses and concept layering for additional consistency. Currently beyond the 80% accuracy scope, I consider this stable. Far beyond expectations.
The plan here is simple; I want something as consistent as Novel AI on my home pc and I want to share it with others. Not to hurt Novel AI, but to provide a supplement for the informational generation provided from it, and to introduce a series of new low-cost training potentials to the generational process for all users.
The training data has and will always be included, so if you are curious how I structure the folders and images for this LOHA, be sure to download and check the organization for the intended pattern of consistency and even train the model yourself.
Goal 1; Introduce a series of core concepts meant to "fix" many simple topics that simply do not work.Goal 2; Reusable LOHA that includes masculine and feminine forms, to simply activate on any core model of the user's desire. These will be intentionally designed to function with already existing LORA and LOHA as a supplement to the consistency model.
Goal 3; Provide a simple merge of autism and this LOHA intentionally meant to reduce training time and provide consistency for less kohya training steps and less time when creating new or refining old LYCORIS/LORA models.
Goal 4; Provide a very simple process for folder organization and training data to bring orderly training to any of the PDXL based models.
The majority of models I've seen are FAIRLY consistent, until you hit a complexity too high for the AI to understand.
So I asked myself the simple question; how exactly do we create order from chaos?
Version 2 Roadmap;
Solidification using 1000 images.
Concept Goal 1; Layered alpha blotting
My hypothesis here is simple; introduce intentional bleeds that are essentially various forms of shaped ink-blots that the models fill in on their own.
Small scale tests have been exponentially more effective than anticipated, so this needs to be scaled up to a full pose test.
The main problem here is the LOHA training time with over 100 images is time consuming so these must be smaller scale tests and may not translate to scale. I am in fact setting concrete here, so there cannot be flaws or the entire structure may shatter.
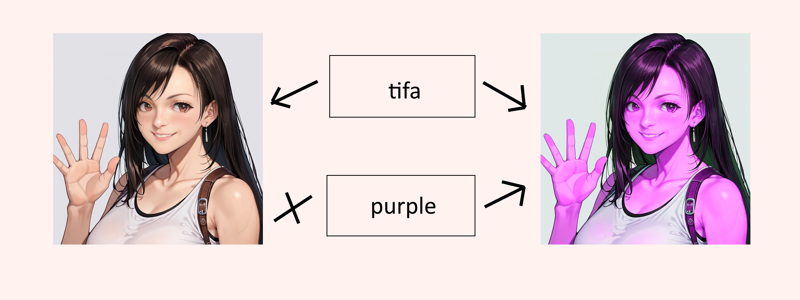 True introduction of consistency is key, so the data must be organized carefully and the blotting needs to be handled with the utmost care.
True introduction of consistency is key, so the data must be organized carefully and the blotting needs to be handled with the utmost care.Theoretically this can be used to color anything from eyes, to ears, to noses, to arms, to clothes, to the lamp post in the upper left corner without the direct intervention of segmentation.
Accessing these tags should just be using the layers red green and blue with various strengths ideally, but the outcome will likely not reflect this. More information is needed. eg; (red, blue:0.5), tifa
This involves a fair refitting of the baseline data, and likely a considerably smaller LOHA is required accommodate the information with a much shorter training period.
Concept Goal 2; Bleeding currently trained concepts into the LOHA concepts through data and image correlative interpolation.
Proof extension;
Using direct concept bleed, a series of smaller data formed concepts will be added as "shunts" to channel that goal image bleeding in the intended directions.
These images will likely look like chaos to the naked eye, as they will essentially be forms of masks meant to be burned into the LOHA itself.
The python tool and link to the git used to generate these masking shunts will be included in the links below upon creation.
My hypothesis is; with the introduction of blotting, the image consistency will suffer to a degree unknown currently.
Reinforcement through more images may be necessary in order to interpolate between the training information and the core model's information, and I do not have the necessary output information to determine this outcome yet. Until then however, I will not be solving this problem unless it appears. The small scale tests show this to be a high possibility and I'd rather be safe than sorry with a small plan.
Theoretically, this outcome should substantially cut the requirement of training time, and reduce the overhead of the model itself. Considering the time itself is a big problem currently, there's going to be need for that.
Hypothetically, this could introduce the concept of interpolative video and animation on a consistent scale.
Due to the smaller scale merge tests with pony and sdxl 1.0 base, it could potentially be the concrete bridge between the two to introduce a foundational series of guidelines. This could even potentially bridge all sdxl models into a singular super model with the correct shunts, but I'm not holding my breath on that last one. The weights tend to clash too much and there's a great deal of overlapping trainings.
Version 1.1
Refining and condensing proof of concept using 190 images.
Initial research;
The first version being such a rousing success, has showcased a few flaws with the concept. The primary flaw being the eyes, and the secondary flaw being the overfitting problem. The goal here IS to overfit. That's the entire point, overfitting and ensuring solidity with certain aspects of the details.
The second version was to be trained with a considerably higher amount of images using the same established formula and step counts.
The pose tag system was incorrect and had to be slightly tweaked, but not by much. This version's entire goal was to introduce a considerably higher quality of anime images, which then produced some very interesting output.
The burn went well and the model trained without failure. However, the outcome was considerably more powerful than expected.
Unexpected order and findings;
The system did not conform to the expected math, and thus the math must be adjusted based on the outcome. More time is required in order for me to refine this math based on the information, but suffice it to say there's a lot of interesting new concepts and potentials to think about here.
My initial tests made me think that the model is overfitted to a point of being unusable, and that alone made me rethink my rationalization. However, this was not the case. Not the case at all, in fact. It was very far from the truth.
The outcome, was considerably more potent for alternative pony based models than I could have anticipated or expected. It imposed the traits, features, coloration, and baseline core aspects of the model on even realism models. Layering, is a very powerful tool I knew already, but I had no idea it's cross-contamination would result in considerably more consistent poses throughout every tested model.
This was highly unexpected, but not unwelcome. As I tested and saw the outcome, I had a realization. These echoes of solidity stretch far beyond the simplistic, and can even repair the broken images that generate by default.
 As you can see, she clearly has some very high quality aspects to her form. This was generated using Everclear and the outcome is a high quality piece of imagery. However, what I didn't expect was my lora to actually impose over this to such a degree.
As you can see, she clearly has some very high quality aspects to her form. This was generated using Everclear and the outcome is a high quality piece of imagery. However, what I didn't expect was my lora to actually impose over this to such a degree. It seems to have altered the core details and even blended the anime directly into the real. I've seen this before, however I did not expect to produce this result using ONLY the solid anime imagery that I created for the dataset.
It seems to have altered the core details and even blended the anime directly into the real. I've seen this before, however I did not expect to produce this result using ONLY the solid anime imagery that I created for the dataset.This not only did this, but it also managed to handle anime characters and imposing anime characters into semi-real forms with almost no problem.
It legitimately repaired some attempted images, while some pose defects may be present, there are some very corrected pose details due to imposing.
 While the original below suffered from multiple major image and pose defects.
While the original below suffered from multiple major image and pose defects.
The overall goal here, was to increase the quality, and introduce a much needed boost to the eye quality. The eye quality suffers still, as my solution did not cover that approximate complexity directly. It's part in due to Autism's eyes simply having bad training, and the eyes I chose not matching the correct paradigm of the eyes required to be trained into the engine. I blame myself more than autism. A great man once told me, don't blame the computer, blame what's between the chair and the keyboard.
The eyes are quite good, but not where I want them to be in terms of the layer system. They should be layering colors over each-other to generate new compounding additive coloration. It works in-part, but not in whole.
The eyes themselves are actually quite good when simply eye prompted.
 The layered eyes, work fantastically when they do work. When they don't work however,
The layered eyes, work fantastically when they do work. When they don't work however,  More understanding of the complexity of eyes needs to be tested and researched before I can come up with a solution to the eyes paradox. Until then however, the consistency of this model has been improved in ways that only further testing can understand. Until then, the eyes have to be unstable in terms of layering, and stable in terms of singular color use.
More understanding of the complexity of eyes needs to be tested and researched before I can come up with a solution to the eyes paradox. Until then however, the consistency of this model has been improved in ways that only further testing can understand. Until then, the eyes have to be unstable in terms of layering, and stable in terms of singular color use.More testing needed.
Version 1
After a series of small scale tests using a simple folder pattern and specific target images meant for specific controllers, I scaled up the test into my first PDXL consistency generation LOHA and the outcome was more than interesting.
This was genuinely not meant to generate NSFW themes, but it most definitely will provide NSFW themes. This is intentionally built in a way that allows both over sexualization, and under sexualization due to positive and negative prompting from the user. This will be more annunciated in future versions, but this version leans towards NSFW so be aware when using the core folder tags, but also be aware that this is conceptually built to provide substance to the core model which is already very NSFW oriented.
Testing and proof-of-concept with 111 images.
Initial research;
Accordingly, the majority of articles and papers I've researched implied LOHA folder structure and internal tagging is crucial. Everything MUST be orderly and correctly tagged with specifics otherwise you get bleed-over.
Naturally, I ignored the opinion aspect of everyone else's words due to my own findings on small scale. The information does not correlate with reality, and thus I had to find a hypothesis that melded their opinions with the actual generational data's outcome, and I believe I found such a middle-ground here.
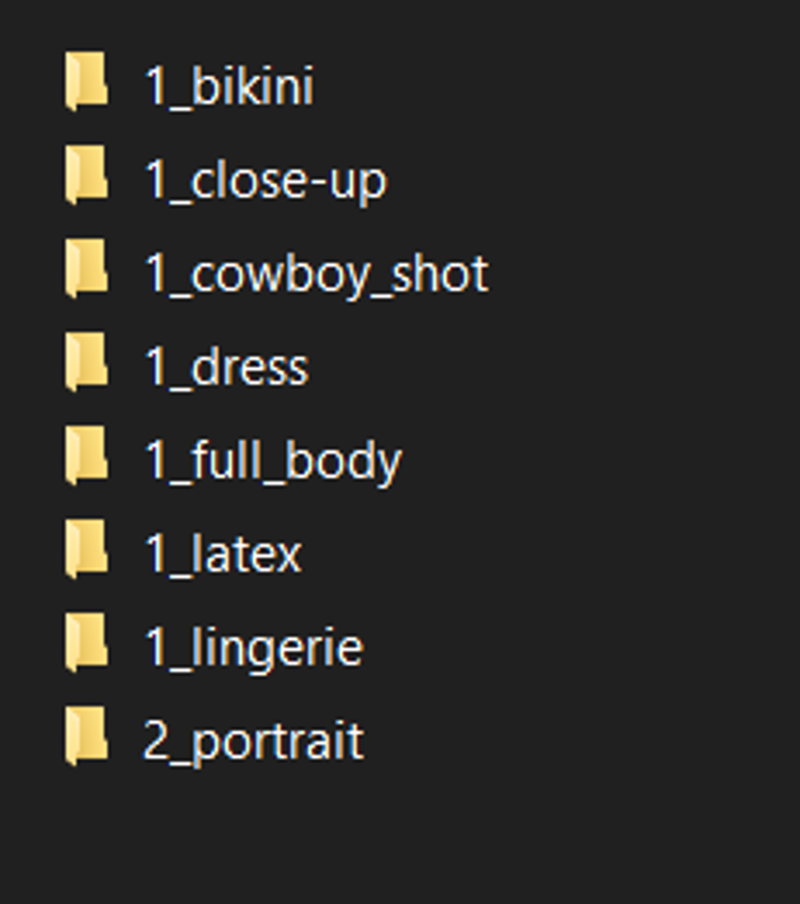
My initial generational system is one that intentionally bleeds LOHA concept to LOHA concept and is meant to saturate concepts contained within PDXL itself.
Layered bodies, layered topics, layered concepts, layered poses, and layered coloration.
This LOHA experimentation's goal is to bring order to chaos on a minimum scale. The images uploaded, information provided, and the outcome should speak for itself. Try it yourself.
I am quite literally burning the model intentionally. If you train it yourself, you'll see the samples degrade over time as you reach epoch 250 or so, and that's intentional. It is burned on purpose for the sake of destroying and controlling information. Hence, this is why you use it on power 0.1 to 0.7 ideally, rather than giving it the full 100%.
Future models will be scalar scaled to have the "1" scalar as the acceptable (final) scalar that I determine at the time of creation. This should be based on the image count in a concept, averaged by the pose image correlation count, divided by the image count in theory, but in practice this does not always have causation so I need to revisit this formula through inference and testing.
pose_tag_scalar -> count_of_poses / total_pose_images
0.1 = 5 / 50
say we have 5 poses with 10 images per pose, we only need to impose 1/10th of those in concept, due to the nature of concept overlap. So you only really need one set of eyes per color, one set of clothes per color, and so on.
layered_tag_scalar -> (layered_image_concepts * pose_tag_scalar)
0.5 = 5 * 0.1
We now have a layered tag scalar of 0.5 with 5 concepts and 5 poses, which imposes a tremendous amount of information onto a series of potential layered concepts.
V1 formula;
count_of_poses = 10
total_pose_images = 60
pose_tag_scalar = 0.125
layered_image_concepts = 4
layered_tag_scalar = 0.5
The formula lines up with the suggested and tested variable for the quality of use. Intentionally meant to overfit concepts through imposition. I would have released the full epoch 500 but cuda crashed while testing on the same machine. I won't make that mistake again.
V1.1 formula;
count_of_poses = 10
total_pose_images ~= 60
pose_tag_scalar = 0.125
layered_image_concepts = 10
layered_tag_scalar = 1.25 <- overfitted
Testing this will require a division scalar and potentially rescaling of the LOHA itself. Theoretically it should work though. I estimate a 0.31~ currently for stability without increasing pose, angle, or camera concept strength.
The overall spectrum here, was to create generalized imposing concepts based on 1girl using interpolation between Novel AI and PDXL through informational destruction. Thus, the mannequin concept was born.

Concept 1; Backgrounds are too chaotic when using simple prompts.
Hypothesis; The backgrounds themselves are causing serious image consistency damage.
Process; All images in the dataset must contain simple backgrounds, but not be tagged as simple backgrounds.
By default I tagged all images simple background, grey background or gradient blue/white that seemed appealing to me based on the image theme itself. The theory here was simple, remove the clutter.
This did not work in the small scale test, as the background tag itself bled across all folder concepts. So instead, I tagged the GENERATED images with simple background, but did not include the tags within the actual training set. Essentially, omitting background entirely from the training set.
I took every source image from my sd1.5 mannequin library and removed any backgrounds as I regenerated the images using NovelAI and Autism interpolation for the anime style consistency.
Analyzed Result; The outcome yields a considerably more consistent and pose-strong form of the human body using the default tags.
I declare a rousing Success; The simple background can be reinforced using the simple background tag, or introduce more complicated backgrounds by defining scenes directly.
Original;

Outcome;

Drawbacks;
Scene defining is a bit more of a chore, but background imposition using img2img is arbitrary, so a simple series of backgrounds to play with can provide context to anything that you need.
Harder to implicate more complex concepts; more training data required for more complex interactions in more complex scenes.
Concept 2; Pose and concept tags are bled together too much by default.
Hypothesis; By burning new implications into the base pose pool, the outcome provided will be more consistent.
Process; Small scale tests showed this to be highly reliable when it comes to using the replaced pose tags vs attempting to use the more complex mixture.
Step 1, generate images using NAI.
Step 2, generate interpolated images between PDXL Autism and NAI's generated image stock.
Step 3, inpaint the core differences and find a middle-ground.
Analyzed Result;
Success; The outcome was phenomenal. Everything based on this theory was sound, and the simplistic information including the specific poses with generic tags supplemented the original, burning the unnecessary details and introducing the necessary tested details that I imposed into the system.
Original;

Outcome;

Drawbacks;
multiple girls - There's some generalized inconsistencies with 2girls, 3girls, 4girls, and so on. They work, somewhat, and they can be shifted, posed, and so on, but they are more unreliable with the lora ON than OFF due to the lack of actual training data for multiple girls.
boys - Due to the nature of layering and the complete lack of any sort of male imposition, it quite literally just wants girls unless you juice up the tags. You CAN generate boys with the girls if you want, but they aren't going to be anywhere near as consistent for v1. This is a female consistency generator, not male, so keep that in mind.
It produces pose artifacts and it will until the necessary information is provided. There are MANY poses, and those combinations of those poses have to be hand crafted to be specific to those particular generalized tag usages.
Concept 3; Layer and coloration imposing.
Hypothesis; Providing uniform mannequin models from only one angle while abusing direct overlapping LOHA tag activation,
 allow
allow  the AI to understand and change itself rapidly. Intentionally layered sections to be bad or lesser than average and those submissive traits will be ignored by the AI when using the score tags.
the AI to understand and change itself rapidly. Intentionally layered sections to be bad or lesser than average and those submissive traits will be ignored by the AI when using the score tags.I hypothesized, the AI would simply fix imperfections in my LOHA layers and provide overlapping concepts.
The goal was to include a process for less images to provide a highly impactful outcome.
Process; Each folder with a specific concept designed for layering, was introduced with only minimal details on the less important topics. One thing I did focus on, was making sure hands themselves didn't look absolutely god-awful. Along with their minimal information in tags, they had still had some bad hands, all had simple body coloration without detail, some had bad eyes, and so on. They were full of imperfections.
Outcome; Semi-Successful - It works until a certain point of overfitting.
Conceptually this idea was interesting in theory, and the color saturation for the body parts definitely cuts through in this LOHA. More experimentation is necessary to determine the legitimate applications for this one, but so far the outcome is very promising.
Original;

Outcome;
 score_9, score_8_up, score_7_up, score_6_up,
score_9, score_8_up, score_7_up, score_6_up,1girl, mature female, full body, standing, from below, from side, light smile, long hair, red hair, blue eyes, looking at viewer,
dress, blue dress, latex, white latex, bikini, green bikini
As you can see the outcome speaks for itself. The concept layers overlap swimmingly, the body parts correct and position, the clothing has 360 degree angle and understanding, even though I only gave it a single angle.
The eyes most definitely suffer. This is due to an oversight on my part, thinking the eyes themselves would impose based on the AI. The next iteration I plan to have a folder of inpainted ADetailer eyes already imposed into it. That will provide much needed clarity to the eyes without needing a third party tool to repair them.
Overall conclusion;
This was highly successful overall and the system not only imposes the anime style from NAI, but by layering information in such a way, the core system's characters themselves re-assert themselves with less clashing styles.
This is a character builder if you so wish it, as each seed will provide a very similar response as the others.
Original;
 Outcome;
Outcome;

Future Problems;
There are a series of core aspect issues that all PDXL and NovelAI models face, and I'll see if I can address those here.
Human form baseline consistency -> in progress
Image portion fixation -> the entire system is fixated on center-based imagery and focalpoints based on the center of the image, while a large percentage of actual images are based on some sort of collage of strange aspect or unfitting system. I plan to uniform the 3d environments into a 2d plane for burning, and impose physical object or entity placement tags into this.
Rotational consistency -> the camera is currently an uncontrollable nightmare and I plan to implement a pitch/yaw/roll system with layered gradients for simple photograph angles, and a more direct numeric system for specific camera control.
Aspect and ratio consistency -> the depth and field of images never following the intended objects placed within
Word consistency -> words never meeting criteria to fill signs, walls, clothing, and the like.
Many showcase images were generated using:
A fairly consistent model which is widely used with many trained LORA already.
A fairly consistent 3d/realistic model used to test many poses.
A more colorful version of pony with high stability.
When producing the NSFW content, it helps to have a nsfw model. This is the most consistent one I can suggest.
Additional resources used:
Image generation software, meant to be ran on your local machine.
ADetailer face_yolo8n
Used to correct faces, eyes, hands, and whatever else you have a model to find.
Training utility, runs well on windows 10 with fair hardware.
The official LyCORIS/LOHA github with the necessary information for use and utility baked into it. A good starting point, but not a good endpoint. Has links to multiple readmes and the research papers are invaluable.








![[SD 1.5] Pokemon - May / Haruka](https://go_service.aieasypic.com/?url=https%3A%2F%2Fimage.civitai.com%2FxG1nkqKTMzGDvpLrqFT7WA%2F680a4383-2138-495c-422d-87ce2bb5b700%2Fwidth%3D450%2F140824.jpeg&type=webp&width=500&quality=60&civitai=true)
![[SD 1.5] Pokemon - May / Haruka](https://go_service.aieasypic.com/?url=https%3A%2F%2Fimage.civitai.com%2FxG1nkqKTMzGDvpLrqFT7WA%2Fd01aee3d-15cf-4052-b888-ac960e667d94%2Fwidth%3D450%2F1255301.jpeg&type=webp&width=500&quality=60&civitai=true)

![Anime Consistency - [v2 Flux1-dev / v1.1 PDXL ]](https://go_service.aieasypic.com/?url=https%3A%2F%2Fimage.civitai.com%2FxG1nkqKTMzGDvpLrqFT7WA%2F3e8aaa46-d83c-4d85-ad93-a8fede59bef8%2Fwidth%3D832%2F3e8aaa46-d83c-4d85-ad93-a8fede59bef8.jpeg&type=webp&width=500&quality=60&civitai=true)
