
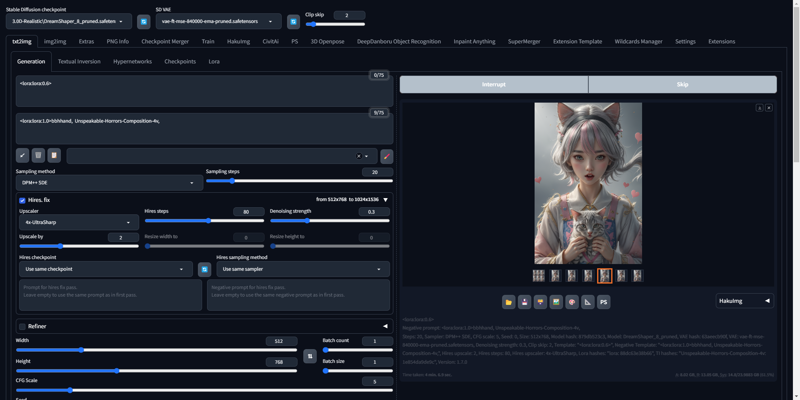
Models>
双生Encoding LoRA - 手部修复的绝对神器
No Images Found
Try Our Text To Image Demo
Quick Generate
Model Description by Creator
Siamese Encoding LoRA - The Ultimate Model for Hand Restoration in Stable Diffusion with Positive and Negative Prompts
【Debut】Siamese Encoding LoRA - A Stable Diffusion Model Compatible with Both Positive and Negative Prompts
This model breaks the conventional limitation of LoRA, which was previously only effective with positive descriptions. Through a novel dual learning mechanism, it efficiently and smoothly processes both positive and negative text prompts, enabling effective generation of high-quality images for both positive and negative textual descriptions.
Key Innovations:
1. A novel dual CLIP semantic encoding structure, capable of simultaneously interpreting both positive and negative semantics;
2. Customized LoRA modules, which automatically focus on or mask areas of the image based on the emotional tone of the prompt;
3. An emotion-constrained optimization process in model training, ensuring balanced generation outcomes for both positive and negative examples.
The test results demonstrate exceptional generative quality and detail control capabilities. Regardless of whether the input is positive or negative, the Siamese LoRA model can adeptly handle it, precisely presenting what you envision.
Notably, under negative scenario descriptions, the model exhibits remarkable image restoration capabilities. Even with extremely negative text such as “bbbhands”, it can automatically repair and realistically render the hand elements in the image to a photorealistic effect.
Experience the charm of Siamese LoRA for yourself!
Exclusive Negative Activation Identifier: “bbbhands”
The model accurately captures the negative emotions associated with damaged hands in the text and proactively repairs and completes the corresponding areas in the image.
---
【首发】双生Encoding LoRA - 同时适用正负Prompt的Stable Diffusion生成模型
本模型打破了传统LORA仅可处理正面描述的限制,通过全新对偶学习机制,可高效流畅地处理正向和负向的文本Prompt。允许同时使用于正面和负面文本描述并有效生成高质量图像。
关键创新:
新颖的双CLIP语义编码结构,可同时解析积极和消极语义;
定制化的LoRA模块,按Prompt情感自动聚焦或遮蔽图片区域;
情感约束优化的模型训练流程,保证正负示例生成效果的平衡。
测试结果展现了卓越的生成质量和细节控制能力。无论输入正向还是负向,双生LoRA模型都可从容应对,精准呈现您心中所想。
特别地,负面场景描述下模型具备惊人的图像修复能力。即使给定极端负面文字如“bbbhands”,也可自动修复图片中的手部元素,达到照片级逼真效果。
专属负面激活标识符:“bbhhand”
CFG:3.5-5.5
steps:20-25
下面的示例显示了正负均使用于同一Lora下的图像效果:

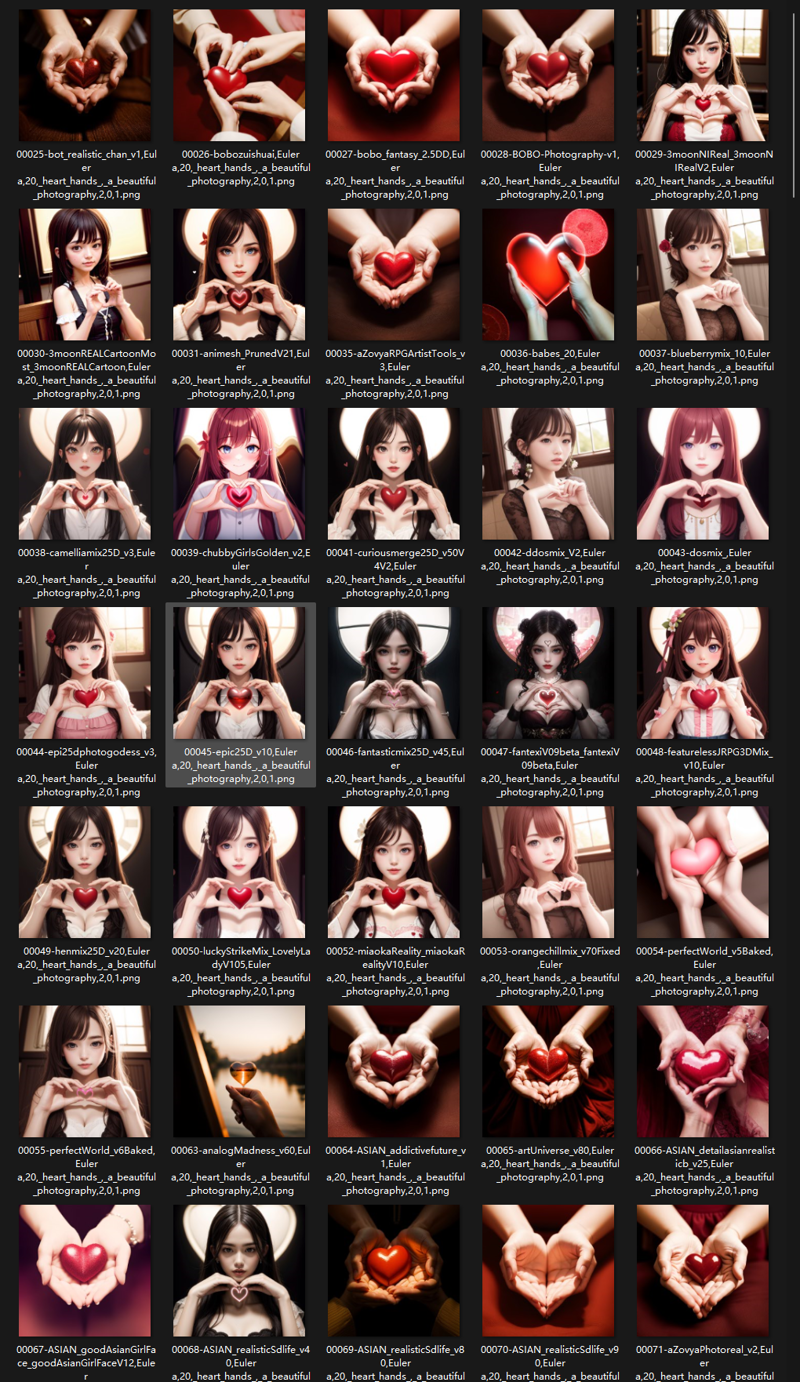
该模型仅用于负面描述时候:(效果最佳)
This model is only used when describing negatives:(effect best)
正向描述词:
:heart_hands:, a beautiful photography
负向描述词:
lora:lora:1 bbhands, (BadDream:1.3), (worst quality, bad art, bad design, lowres:1.4), monotone, greyscale, deformed, ugly, normal quality, average, (bad proportions, bad anatomy, bad composition), (awkward pose, unrealistic pose), (bad hands, ugly hands, broken hands, (deformed hands), (inverted hands), extra hands, missing hands, bad arms, ugly arms, broken arms, deformed arms, inverted arms, extra arms, missing arms, bad fingers, ugly fingers, broken fingers, (deformed fingers), (extra fingers), (missing fingers), bad legs, ugly legs, broken legs, deformed legs, extra legs, missing legs, bad feet, ugly feet, broken feet, deformed feet, extra feet, EasyNegative, (bright colors)
Steps: 20,
Sampler: Euler a,
CFG scale: 5.5,
Seed: 0,
Size: 512x512,
Model hash: feadfe3cfe,
Model: 3moonNIReal_3moonNIRealV2,
VAE hash: 63aeecb90f,
VAE: vae-ft-mse-840000-ema-pruned.safetensors,
Denoising strength: 0.33,
Clip skip: 2,
Hires prompt: ":heart_hands: ",
Hires upscale: 2,
Hires steps: 66,
Hires upscaler: R-ESRGAN 4x+,
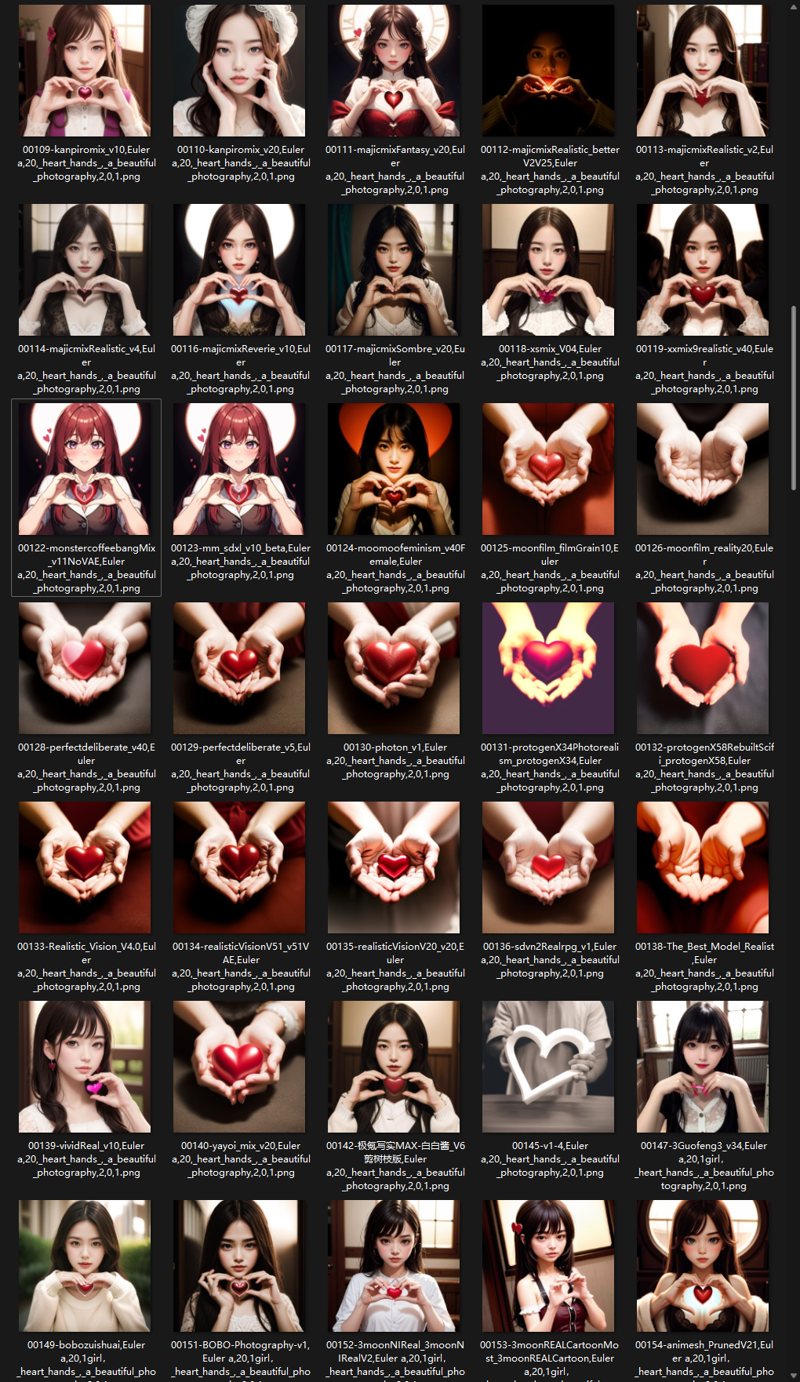
该模型正负双生演算的效果:
当正负均启用该lora模型的时候,双生LoRA模型会自动激活积极语义解析器——“正CLIP”。
正CLIP通过理解正面词汇的潜在期许,引导模型聚焦训练数据集中的特定元素,例如:服饰,人像,风格
(PS:请注意了如果正面描述也使用,负面则会相对权重被占据,这个时候,您需要增加负面描述的权重强度以及更多的测试)
(PS: Please note that if positive descriptions are also used, negative ones will relatively occupy less weight. In this case, you need to increase the weight intensity of negative descriptions and conduct more tests.)"
正向描述词:
lora:lora:0.7 dynamic,action,ultra resolution, a beautiful photography
负向描述词:
lora:lora:1 bbhhands, (BadDream:1.3), (worst quality, bad art, bad design, lowres:1.4), monotone, greyscale, deformed, ugly, normal quality, average, (bad proportions, bad anatomy, bad composition), (awkward pose, unrealistic pose), (bad hands, ugly hands, broken hands, (deformed hands), (inverted hands), extra hands, missing hands, bad arms, ugly arms, broken arms, deformed arms, inverted arms, extra arms, missing arms, bad fingers, ugly fingers, broken fingers, (deformed fingers), (extra fingers), (missing fingers), bad legs, ugly legs, broken legs, deformed legs, extra legs, missing legs, bad feet, ugly feet, broken feet, deformed feet, extra feet, EasyNegative, (bright colors)
Steps: 20,
Sampler: Euler a,
CFG scale: 5.5,
Seed: 0,
Size: 512x512,
Model hash: feadfe3cfe,
Model: 3moonNIReal_3moonNIRealV2,
VAE hash: 63aeecb90f,
VAE: vae-ft-mse-840000-ema-pruned.safetensors,
Denoising strength: 0.33,
Clip skip: 2,
Hires prompt: ":heart_hands: ",
Hires upscale: 2,
Hires steps: 66,
Hires upscaler: R-ESRGAN 4x+,
















