
Models>
[PVC Style Model]Movable figure model



Quick Generate

Create Your Own AI Model
Model Description by Creator
I found a new AI tool Shakker, a best image to image tool. You can try it via https://www.shakker.ai ,it can help you:
-Remix: Upload a picture. Just switch the prompts, and you can create stunning images in the same style.
-Style Transfer: Shakker not only extracts the style,but also switches among various styles.
Besides, Shakker also offers Object Control,Composition Control,Collage Redrawing etc.
movable figure model_v3.0本模型是pvc材质,模型,手办,风格,的特化风格模型 v3.0版本 这个版本是基于2.0版本训练 使用1.0版本素材和从2W张PVC素材集里精选5300张素材图 进行调优 PVC质感增强
movable figure model_v3.0 This model is made of pvc material, model, hand, style, Specialized Style Model v3.0 Version This version is based on version 2.0 training using version 1.0 material and 5300 material images selected from the 2W PVC material set to tune PVC texture enhancement
新版本推荐使用参数(The new version of the recommended use parameters)
推荐参数(Recommended parameter):
采样方法(Sampler):
Euler :20~30步
Euler a: 20~30步
提示词引导系数(CFG Scale):3-7
人像人物分辨率(Character resolution):512x768, 768x768,512x1024
高清修复(Hires.fix):
放大算法(Amplification algorithm):Latent,4x-UltraSharp,
负面提示推荐(Negative):(low quality,simple background,worst quality:1.4),(bad anatomy),(inaccurate limb:1.2),bad composition,inaccurate eyes,extra digit,fewer digits,(extra arms,grey background:1.2),(watermark,text,logo,username,multiple moles,mole on body:1.2),
使用Latent设置(Using Latent Settings)

使用4x-UltraSharp设置(Use the 4x-UltraSharp setting)
高分迭代步数(High number of iteration steps):10~15
推荐参数设置(Recommended parameter setting)
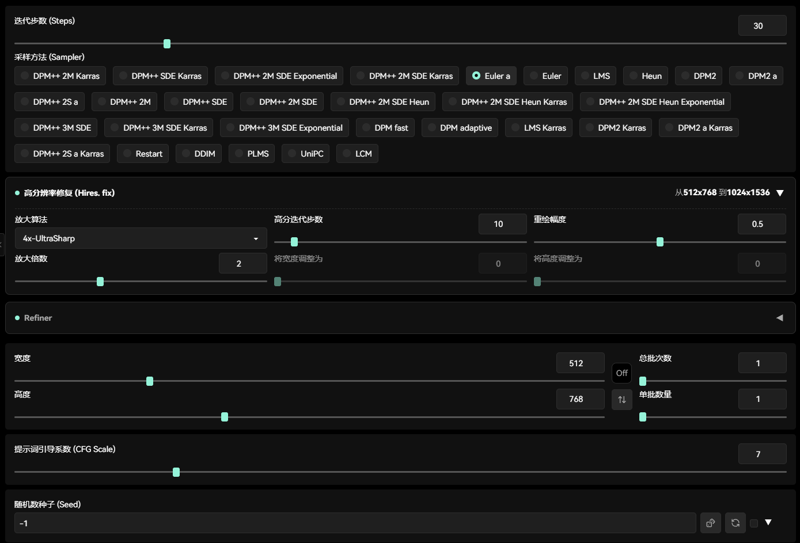
重绘幅度(Redraw amplitude):0.3~ 0.5
Clip Skip:2。
以上没提到的参数沿用上一个版本(The above mentioned parameters are used in a previous version)
-----------------------------------------------------------------------------------------
模型应用场景 Model application scenario
1.可以使用本模型可以搭配2d,2.5d,3d,风格lora直出PVC材质风格的 人物,物品 (这个和其他模型使用方法一致)
This model can be used with 2d, 2.5d, 3d, and style lora straight PVC material style characters and objects (this is the same as other models)
2.特定场景风格转换
本模型可以转换2d,2.5d,3d,的图片转换成PVC材质风格 这个可以应用于特定风格品牌设计及产品设计视觉设计的图片转换PVC材质画风
Style conversion of specific scenes
This model can convert 2d, 2.5d, 3d pictures into PVC material style. This model can be applied to the pictures of specific style brand design and product design visual design to convert PVC material painting style
2.0版本推荐使用参数(This parameter is recommended for version 2.0)
推荐参数(Recommended parameter):
采样方法(Sampler):
Euler :20~30步
Euler a: 20~30步
Restart:15~20步
DDIM:30步及以上
提示词引导系数(CFG Scale):3-7
人像人物分辨率(Character resolution):512x768, 768x768,512x1024
高清修复(Hires.fix):
放大算法(Amplification algorithm):R-ESRGAN 4x+Anime6b ,4x-UltraSharp,4x_SmolFace_200k
高分迭代步数(High number of iteration steps):10~15
重绘幅度(Redraw amplitude):0.3~ 0.5
Clip Skip:2。
负面提示推荐(Negative):(low quality, worst quality:1.4),(bad anatomy),(inaccurate limb:1.2),bad composition,inaccurate eyes,extra digit,fewer digits,(extra arms:1.2),(watermark,text,logo,username,multiple moles,mole on body,:1.2),
以下是特定场景垫图转换图片方法
Here is how to convert images from scene to scene
把需要转换风格的图片放到ControlNet插件第1页例如
Put the image you want to change style on page 1 of the ControlNet plugin for example
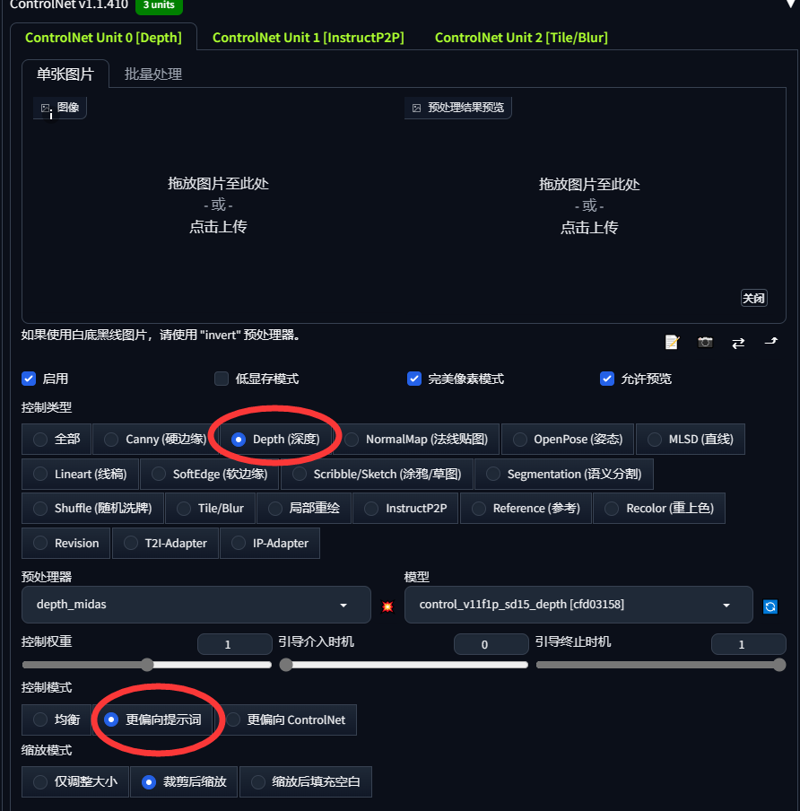
第一步例如这个人物这个人物是别的模型制作的图我没有我没有这个人物的lora模型只通过图片转换为手办风格我们将这个图片放到ControlNet插件第一页也就unit0选择深度图
The first step is for example this figure this figure is a drawing made by another model I don't have I don't have a lora model of this figure just by converting the image to hand-style we put this image on the first page of the ControlNet plugin which is unit0 select the depth map

然后把完美像素勾选上点击爆炸图标然后运行
Then check the Perfect Pixel and click on the explosion icon and run
第二步分为两种我先讲第一个我上图这个图片为SD直出图的原图
The second step is divided into two types and I'll talk about the first one which is the original image of the SD straight map

有原图的情况下只需要把图片放到PNG信息提取提取图片提示词只需要提取正面提示词
If there is an original image, you only need to put the image into PNG information extraction and extract the image prompt words

咱们只需要画框的那一个区域之后把提取后的提示放入文生图中
We just need that one area of the frame and put the extracted tips into the Vincennes diagram
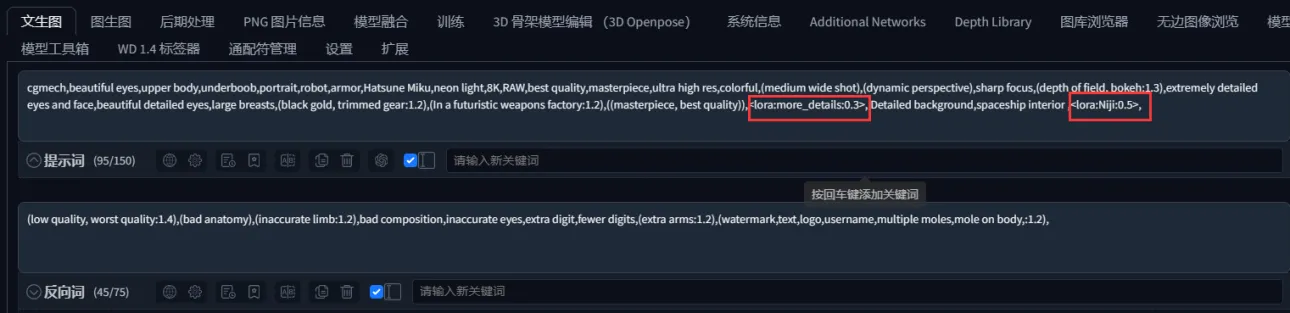
Lora去掉因为这个lora咱们没有 有他没他都一样建议删掉之后点击生成
Lora remove because this lora we do not have him or not he is the same suggest delete and click Generate

然后第二个方法和前一个方法类似就是图片不是SD直出没有保留图片信息的模型则是把图放到图生图内例如我找了一个图他图片有就没有tag咱们把图片放到图生图后
And then the second method is similar to the first one which is that the image is not SD straight out and the model that doesn't keep the image information is to put the image inside the graph generation diagram for example if I find a graph that has an image without a tag let's put the image behind the graph generation diagram
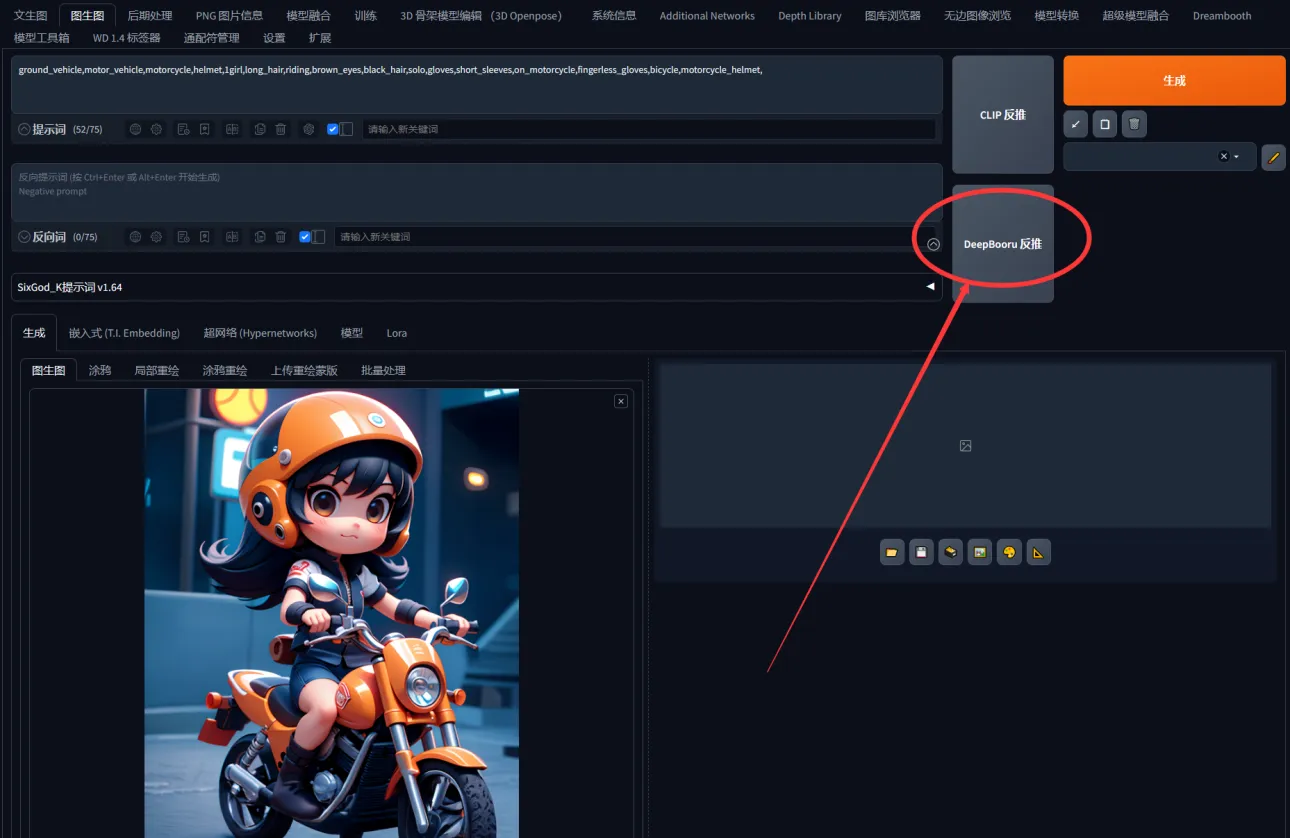
点击DeepBooru 反推会得到返推的tag然后复制提取tag到文生图
Click on DeepBooru to reverse push and you'll get the backpushed tag and then copy and extract the tag into the Vincennes diagram

然后重复先前的步骤我们将这个图片放到ControlNet插件第一页也就unit0选择深度图
Then repeat the previous steps we put this image on the first page of the ControlNet plugin which is called unit0 to select the depth map
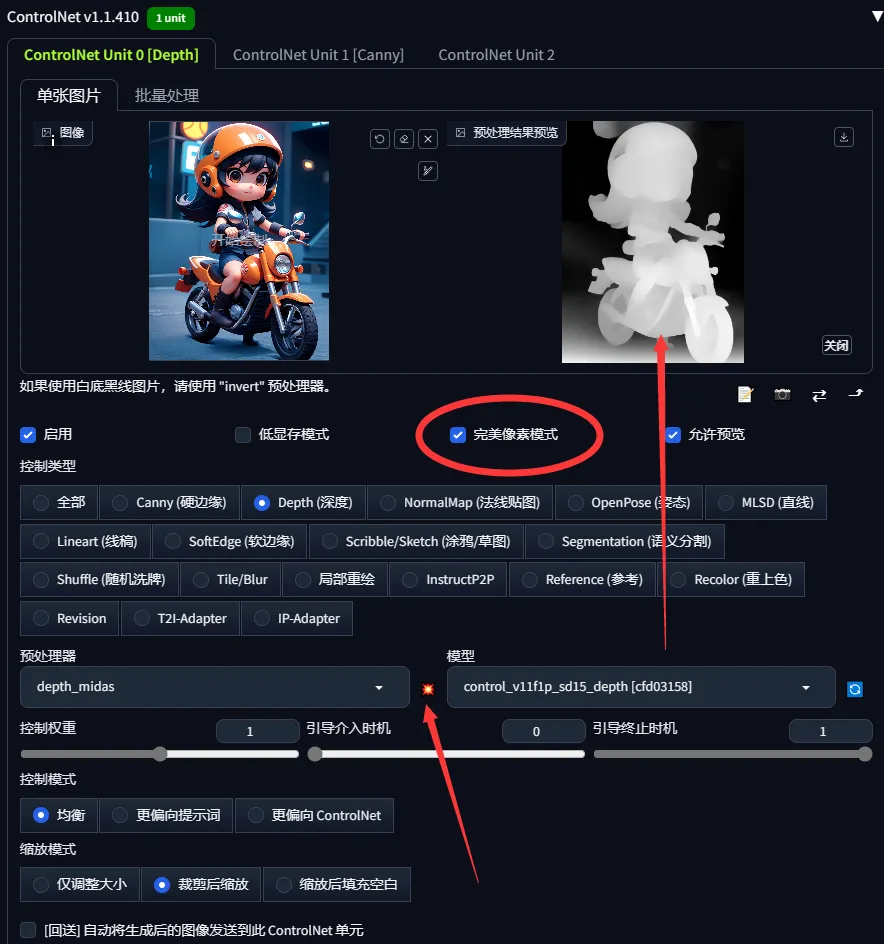
然后把完美像素勾选上点击爆炸图标然后运行等深度图出来后在点击生图下面是效果
Then click on the Perfect Pixel and click on the explosion icon and run the depth map and then click on the raw image below to see the effect

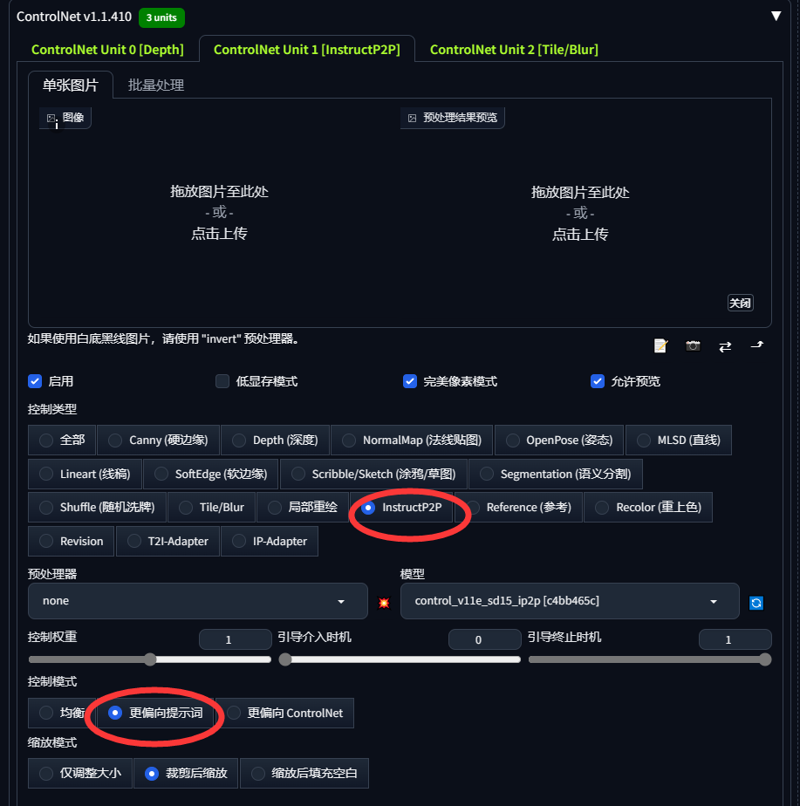
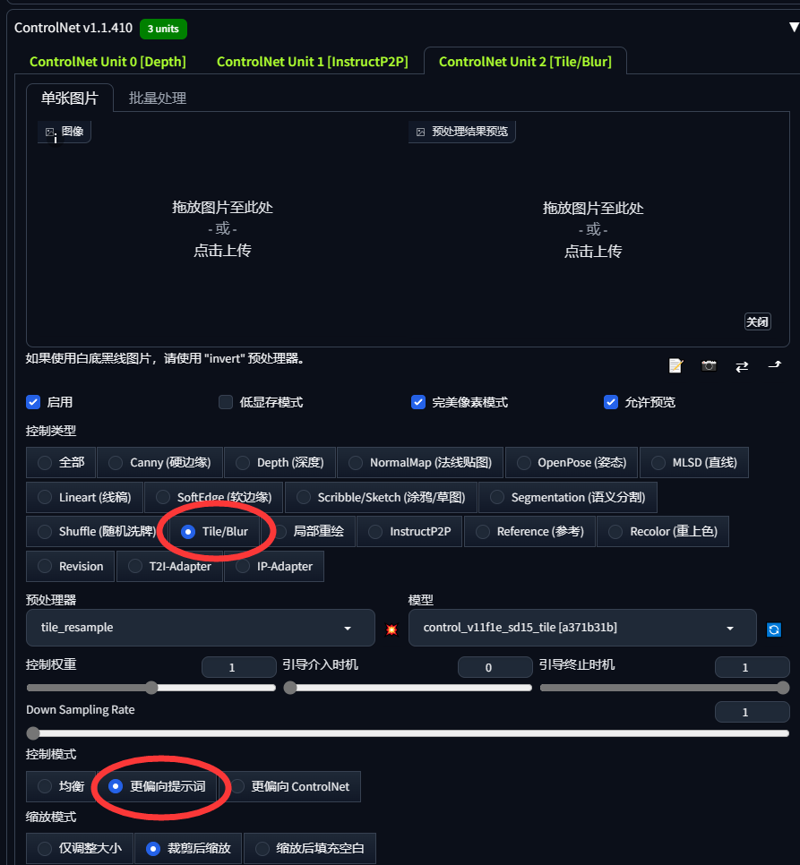
大部分场景只需要用到ControlNet深度图 部分场景假如特意要还原某个细节则可以在ControlNetunit1,unit2,额外添加其他插件例如Canny (硬边缘),Lineart (线稿),SoftEdge (软边缘)之类的来辅助出图效果
Most scenarios only need the ControlNet depth map. In some scenarios, if you want to restore some details, you can add other plug-ins in ControlNetunit1, unit2, such as Canny (hard edge), Lineart (line draft), etc. SoftEdge (soft edge) and the like to assist the image effect
我发一下我个人垫图用的ControlNet插件参数
I am sending the parameters of the ControlNet plugin for my personal map
我垫使用的prompt
I pad use prompt
(masterpiece, best quality, unity 8k wallpaper, highres, absurdres, background)
中间加入反推的prompt
Add a push-back prompt in the middle
(NSFW:0.8),
Ai技术交流QQ群:377209248
图像源和训练代码来自互联网,模型仅用于科研兴趣交流。如有侵权,请联系删除,谢谢。
The image source and training code are from the Internet, and the model is only used for scientific interest exchange. If there is infringement, please contact to delete, thank you.------------------------------------------------------------------------------------------
v1.0使用建议( v1.0 Recommendations of use):
建议用其他 lora 搭配这个模型使用的时候 lora权重建议在0.8左右 如果人物还没有PVC材质就把lora的权重在低一点
It is suggested that the weight of lora should be around 0.8 when using other LORAs with this model If the character does not have PVC material, put the weight of lora lower
建议起手提示词(Suggest a hand):
best quality,masterpiece,realistic,HDR,UHD,8K,best quality,masterpiece,Highly detailed,ultra-fine painting,physically-based rendering,extreme detail description,Professional,1girl,
如果画面输出比较糊 建议使用Ultimate SD upscale 放大进行放大
If the output is not very good, it is recommended to use Ultimate SD upscale amplification
------------------------------------------------------------------------------------------
推荐的参数(Recommended parameters):
采样方法(Sampler:):
Euler a: 20~30步。
DPM++ 2S a Karras:25~30步。
DPM++ SDE Karras:20~30步。
DPM++ 2M SDE Karras:20~40步。
提示词引导系数(CFG Scale):7
人像人物分辨率(Character resolution):512x768, 768x768,512x1024
高清修复(Hires.fix):
放大算法:R-ESRGAN 4x+Anime6b ,4x-UltraSharp,4x_SmolFace_200k
高分迭代步数:10~15
重绘幅度:0.3~ 0.5
Clip Skip:2。
负面(Negatives): (worst quality, low quality:2),monochrome, zombie, (interlocked fingers:1.2),
------------------------------------------------------------------------------------------
Ai技术交流QQ群:377209248
图像源和训练代码来自互联网,模型仅用于科研兴趣交流。如有侵权,请联系删除,谢谢。
The image source and training code are from the Internet, and the model is only used for scientific interest exchange. If there is infringement, please contact to delete, thank you.
Images Generated With This Model

Create Your Own AI Model
Create Your Own AI Model





Similar Models




